
Hi guys,
I found roundcubemail a few weeks ago and found it really great. I was a long time Horde-Imp User but roundecubemail is much faster, nicer and easier. But the first thing i miss was a "better" adressbook. I talked about this to thomas and he pointed me to the Ticket #1332930.
Then i have included a lot fields into the database table and made this fields available under the adressbook. The fields i added now are all fields with are needed for vcard 2.1 support (export and import can then be done easier). But the problem now is, that the "right side" for each contact is a long list and maybe not everybody needs the field "tel work 2" for example.
i will put my updates tomorrow to svn - but then i have to think about a nice and fast solution for users that they can change what fields they what to see for here contacts and which fields should be faded out. maybe this can be done like the folder settings under settings or maybe there is a better solution...
i hope you can follow me - my english is not the best ;) - you can see it in svn tomorrow.
roundecubemail is really good - thank you all.
-- Best regards Tobias 'tri' Richter
Visit me at: http://tobias.datenwerkstatt-richter.de/

On Wed, 9 Aug 2006 21:03:53 +0200, Tobias 'tri' Richter maillists@datenwerkstatt-richter.de wrote:
Hi guys,
I found roundcubemail a few weeks ago and found it really great. I was a long time Horde-Imp User but roundecubemail is much faster, nicer and easier. But the first thing i miss was a "better" adressbook. I talked about this to thomas and he pointed me to the Ticket #1332930.
Then i have included a lot fields into the database table and made this fields available under the adressbook. The fields i added now are all fields with are needed for vcard 2.1 support (export and import can then be done easier). But the problem now is, that the "right side" for each contact is a long list and maybe not everybody needs the field "tel work 2" for example.
i will put my updates tomorrow to svn - but then i have to think about a nice and fast solution for users that they can change what fields they what to see for here contacts and which fields should be faded out. maybe this can be done like the folder settings under settings or maybe there is a better solution...
I would look at how the left side uses a scroll bar when it's needed, and mimic that on the right side. Other idea would be to show the imput forms that are available now, and include a 'More >>' link for folks to click which would reveal the rest of the fields (and demand a scollbar if needed)
i hope you can follow me - my english is not the best ;) - you can see it in svn tomorrow.
Looking forward to checking it out, and your english is fine; thanks for making the attempt!
P
roundecubemail is really good - thank you all.
-- Best regards Tobias 'tri' Richter
Visit me at: http://tobias.datenwerkstatt-richter.de/
-- This message has been scanned for viruses and dangerous content by MailScanner, and is believed to be clean.
-- http://fak3r.com - you don't have to kick it

2006/8/9, Tobias 'tri' Richter maillists@datenwerkstatt-richter.de:
Hi guys,
I found roundcubemail a few weeks ago and found it really great. I was a long time Horde-Imp User but roundecubemail is much faster, nicer and easier. But the first thing i miss was a "better" adressbook. I talked about this to thomas and he pointed me to the Ticket #1332930.
Then i have included a lot fields into the database table and made this fields available under the adressbook. The fields i added now are all fields with are needed for vcard 2.1 support (export and import can then be done easier). But the problem now is, that the "right side" for each contact is a long list and maybe not everybody needs the field "tel work 2" for example.
My idea was to create a javascript driven input form that lets the user create and remove the fields he/she needs for the current address (like the Apple Address Book or Gmail does). All field data is then put together into once vCard string and saved in ONE database field. I don't like the idea of having 200 fields in the contacts table and adding one more field each week after somebody called for it.
i will put my updates tomorrow to svn - but then i have to think about a nice and fast solution for users that they can change what fields they what to see for here contacts and which fields should be faded out. maybe this can be done like the folder settings under settings or maybe there is a better solution...
We should create a new branch for this and commit the changes there until we have a final solution. It seems to be a bigger task and I tend to have the trunk only for quick fixes and use branches for new feature implementations.
i hope you can follow me - my english is not the best ;) - you can see it in svn tomorrow.
Regards, Thomas
Eric Stadtherr wrote:
Should rev306 be backed out then? It goes against this concept.
Well, my explanations haven't been clear enough when I talked to Tobias... I'll take care of that, but it definitely goes against my ideas.
I don't see any reason to have lots of fields in the database if we choose a format that can be parsed fast and allows us interchange the data with other formats for import/export/sync. If searching the contacts gets a problem I suggest to create a fulltext index with all field values required for search.
Please don't hesitate to post your opinions to the addressbook/database design.
Regards, Thomas

I dont think that saving the all the field data in one vcard string is a good idea.
How about searching my contacts that live on some city, some info that is in this vcard string?
It isnt good to add a field to each contact info that is available...
I think that can be created 2 tables, one with the contact info type and one that has an 1-n relationship between the contacts table and tis contact info type table, where u can put the info.
Then u can search freely withouth performance issues and store and extends all the contact info without having too many empty fields.
Michel Moreira
2006/8/10, Eric Stadtherr estadtherr@gmail.com:
Should rev306 be backed out then? It goes against this concept.
On Thu, 10 Aug 2006 10:03:06 +0200, "Thomas Bruederli" wrote: 2006/8/9, Tobias 'tri' Richter :
Hi guys,
I found roundcubemail a few weeks ago and found it really great. I was a
long
time Horde-Imp User but roundecubemail is much faster, nicer and easier.
But
the first thing i miss was a "better" adressbook. I talked about this to thomas and he pointed me to the Ticket #1332930.
Then i have included a lot fields into the database table and made this
fields
available under the adressbook. The fields i added now are all fields with
are
needed for vcard 2.1 support (export and import can then be done easier).
But
the problem now is, that the "right side" for each contact is a long list
and
maybe not everybody needs the field "tel work 2" for example.
My idea was to create a javascript driven input form that lets the user create and remove the fields he/she needs for the current address (like the Apple Address Book or Gmail does). All field data is then put together into once vCard string and saved in ONE database field. I don't like the idea of having 200 fields in the contacts table and adding one more field each week after somebody called for it.
i will put my updates tomorrow to svn - but then i have to think about a
nice
and fast solution for users that they can change what fields they what to
see
for here contacts and which fields should be faded out. maybe this can be
done
like the folder settings under settings or maybe there is a better
solution...
We should create a new branch for this and commit the changes there until we have a final solution. It seems to be a bigger task and I tend to have the trunk only for quick fixes and use branches for new feature implementations.
i hope you can follow me - my english is not the best ;) - you can see it
in
svn tomorrow.
Regards, Thomas

I did hesitate to send this, for the sole reason that it proposes additional requirements; but isn't LDAP designed to do exactly what is wanted here? In fact, I was under the (perhaps incorrect) impression that someone was already making progress on an LDAP address book feature. This also has the additional benefit that it can be made compliant with using LDAP address books on userland software (ie: Outlook, Thunderbird, etc.).
Unless I miss something, that would provide exactly those features that are being requested.
On 8/10/06, Thomas Bruederli roundcube@gmail.com wrote:
Eric Stadtherr wrote:
Should rev306 be backed out then? It goes against this concept.
Well, my explanations haven't been clear enough when I talked to Tobias... I'll take care of that, but it definitely goes against my ideas.
I don't see any reason to have lots of fields in the database if we choose a format that can be parsed fast and allows us interchange the data with other formats for import/export/sync. If searching the contacts gets a problem I suggest to create a fulltext index with all field values required for search.
Please don't hesitate to post your opinions to the addressbook/database design.
Regards, Thomas
Hi,
if the rev306 patch doesn`t fit into the concept i'm sorry, i got it wrong. my thought was to have all vcard 2.1 fields in the contact table. i'm no longer sure about that but i thought that only these fields which i created in the contact database table are allowed in the vcard 2.1 standard. So there is no need to have more then these fields in the database or otherwise you break the vcard 2.1 standard. There is also a newer vcard 3.0 standard but this standard isn't very common and there are only a few fields which are new.
2006/8/10, Eric Stadtherr estadtherr@gmail.com:
Should rev306 be backed out then? It goes against this concept.
no problem about that - my patch was only a idea to improve the addressbook, if there are other ideas or concepts it will be great.
to make the addressbook look better even with all vcard fields in the database, it can be a option to show only these fields which are filled. And then if you edit the contact there can be a new button somewhere to view all fields. If you then fill a field which wasn't shown before (because it wasn't filled), it is shown after you saved your changes for the processed contact.
-- have a nice weekend and best regards Tobias 'tri' Richter
Visit me at: http://tobias.datenwerkstatt-richter.de/

Tobias 'tri' Richter wrote:
to make the addressbook look better even with all vcard fields in the database, it can be a option to show only these fields which are filled. And then if you edit the contact there can be a new button somewhere to view all fields. If you then fill a field which wasn't shown before (because it wasn't filled), it is shown after you saved your changes for the processed contact.
That's exactly what I'd like to see :)
mtu
You right with LDAP. There's LDAP access implemented but only for searching and copying to the local address book. I think we should not only rely on LDAP only because not everybody has set up an LDAP server to access it. A local address book should be part of the package and used by default. Maybe we could add some more abstraction that would let us replace the local address book with an existing LDAP account just by configuration. Nevertheless we need to implement a user interface for address management that complies the expectations of a RoundCube user.
Unfortunately I don't have access to an LDAP directory which makes it impossible for me work on that or even to make some concrete suggestions.
~Thomas
Kirktis wrote:
I did hesitate to send this, for the sole reason that it proposes additional requirements; but isn't LDAP designed to do exactly what is wanted here? In fact, I was under the (perhaps incorrect) impression that someone was already making progress on an LDAP address book feature. This also has the additional benefit that it can be made compliant with using LDAP address books on userland software (ie: Outlook, Thunderbird, etc.).
Unless I miss something, that would provide exactly those features that are being requested.
Tobias 'tri' Richter wrote:
Hi,
if the rev306 patch doesn`t fit into the concept i'm sorry, i got it wrong. my thought was to have all vcard 2.1 fields in the contact table. i'm no longer sure about that but i thought that only these fields which i created in the contact database table are allowed in the vcard 2.1 standard. So there is no need to have more then these fields in the database or otherwise you break the vcard 2.1 standard. There is also a newer vcard 3.0 standard but this standard isn't very common and there are only a few fields which are new.
2006/8/10, Eric Stadtherr estadtherr@gmail.com:
Should rev306 be backed out then? It goes against this concept.
no problem about that - my patch was only a idea to improve the addressbook, if there are other ideas or concepts it will be great.
to make the addressbook look better even with all vcard fields in the database, it can be a option to show only these fields which are filled. And then if you edit the contact there can be a new button somewhere to view all fields. If you then fill a field which wasn't shown before (because it wasn't filled), it is shown after you saved your changes for the processed contact.
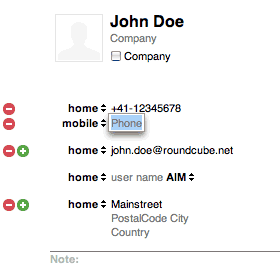
Mac or GMail users might already know what I'm talking out, others please see the attached image. I imagine a dynamic address edit form that lets the user create new input fields and address sections as he/she needs them.
My first intension was to save all data "serialized" as a vCard or Lfid string in one single database field and unpack it when needed. But I also like the suggestion of Eric having a table holding all the vCard fields and values and meanwhile I'd prefer that solution.
Once again, I hope you all understand my ideas about the design of the "new" address book. It's a bit more complex than just having one table and 50 fields to edit and that's also the reason why I haven't implemented it yet. It should be more RoundCube-like :-)
Regards, Thomas

On Aug 11, 2006, at 6:58 AM, Thomas Bruederli wrote:
You right with LDAP. There's LDAP access implemented but only for searching and copying to the local address book. I think we should not only rely on LDAP only because not everybody has set up an LDAP server to access it. A local address book should be part of the package and used by default. Maybe we could add some more abstraction that
would let us replace the local address book with an existing LDAP account
just by configuration. Nevertheless we need to implement a user interface for address management that complies the expectations of a RoundCube user.Unfortunately I don't have access to an LDAP directory which makes it impossible for me work on that or even to make some concrete
suggestions.
What if someone volunteered a LDAP database? ;-)
-- Jason Dixon DixonGroup Consulting http://www.dixongroup.net
Jason Dixon wrote:
Unfortunately I don't have access to an LDAP directory which makes it impossible for me work on that or even to make some concrete suggestions.
What if someone volunteered a LDAP database? ;-)
I would be happy to play around with a LDAP account. But maybe there are other people with more LDAP experience who can implement that LDAP access. All we need is to create an interface/class that can handle all data access to the address book. One can implement the local address book, somebody else the LDAP access.
~Thomas

While on the subject of address book fields - I haven't checked the vCard 2.1 standard, but could we add a photo field? It would be optional to fill in of course, but it would be nice to have the option.
/Martin.
On Fri, 11 Aug 2006 13:12:13 +0200, Thomas Bruederli roundcube@gmail.com wrote:
Tobias 'tri' Richter wrote:
Hi,
if the rev306 patch doesn`t fit into the concept i'm sorry, i got it
wrong. my thought was to have all vcard 2.1 fields in the contact table. i'm no longer sure about that but i thought that only these fields which i created in the contact database table are allowed in the vcard 2.1 standard. So there is no need to have more then these fields in the database or otherwise you break the vcard 2.1 standard. There is also a newer vcard 3.0 standard but this standard isn't very common and there are only a few fields which are new.
2006/8/10, Eric Stadtherr estadtherr@gmail.com:
Should rev306 be backed out then? It goes against this concept.
no problem about that - my patch was only a idea to improve the
addressbook,
if there are other ideas or concepts it will be great.
to make the addressbook look better even with all vcard fields in the
database, it can be a option to show only these fields which are filled. And then if you edit the contact there can be a new button somewhere to view all fields. If you then fill a field which wasn't shown before (because it wasn't filled), it is shown after you saved your changes for the processed contact.
Mac or GMail users might already know what I'm talking out, others please see the attached image. I imagine a dynamic address edit form that lets the user create new input fields and address sections as he/she needs them.
My first intension was to save all data "serialized" as a vCard or Lfid string in one single database field and unpack it when needed. But I also like the suggestion of Eric having a table holding all the vCard fields and values and meanwhile I'd prefer that solution.
Once again, I hope you all understand my ideas about the design of the "new" address book. It's a bit more complex than just having one table and 50 fields to edit and that's also the reason why I haven't implemented it yet. It should be more RoundCube-like :-)
Regards, Thomas

On Thu, 10 Aug 2006, Thomas Bruederli wrote:
Eric Stadtherr wrote:
Should rev306 be backed out then? It goes against this concept.
Well, my explanations haven't been clear enough when I talked to Tobias... I'll take care of that, but it definitely goes against my ideas.
I don't see any reason to have lots of fields in the database if we choose a format that can be parsed fast and allows us interchange the data with other formats for import/export/sync. If searching the contacts gets a problem I suggest to create a fulltext index with all field values required for search.
I see two problems here:
- Anyone working on DB design would have stomach aches seeing it. :-)
Raelly, the problem could raise later because of the non-normalize database design. 2) Not all the database engines have good full text search indexes, and they tend to consume more resources.
I personally think that if we are gonna put and get data without searching, maybe it can all go in one field. Else, it makes it dificult to make the searches, and even worst, at the PHP side it's dificult to look for words in diferent sectors of the text field.
If you put it all in one text field, you'll have real headaches in the future. Trust me on this. ;-)
-- 21:50:04 up 2 days, 9:07, 0 users, load average: 0.92, 0.37, 0.18
Lic. Martín Marqués | SELECT 'mmarques' || Centro de Telemática | '@' || 'unl.edu.ar'; Universidad Nacional | DBA, Programador, del Litoral | Administrador
On Thu, 10 Aug 2006, Michel Moreira wrote:
I dont think that saving the all the field data in one vcard string is a good idea.
How about searching my contacts that live on some city, some info that is in this vcard string?
It isnt good to add a field to each contact info that is available...
I think that can be created 2 tables, one with the contact info type and one that has an 1-n relationship between the contacts table and tis contact info type table, where u can put the info.
Then u can search freely withouth performance issues and store and extends all the contact info without having too many empty fields.
This is a good idea. can we through some ideas on DB structure?
-- 21:50:04 up 2 days, 9:07, 0 users, load average: 0.92, 0.37, 0.18
Lic. Martín Marqués | SELECT 'mmarques' || Centro de Telemática | '@' || 'unl.edu.ar'; Universidad Nacional | DBA, Programador, del Litoral | Administrador

On Aug 11, 2006, at 7:11 AM, Eric Stadtherr wrote:
I agree with not relying solely on LDAP. Requiring LDAP for the
local address book imposes yet another installation/configuration/ maintenance/support requirement on the RoundCube administrator.
Also, for people who are hosting RoundCube on third-part web
servers, LDAP may not even be an option.Having said that, LDAP is a very common directory service provider
for many companies and I think we need to support LDAP seamlessly.
Many e-mail clients (Thunderbird, Apple Mail) support read-only
access to LDAP directories as a supplement to their local address
book. I like this model, which is generally where RoundCube is
headed right now. There are some things we could do to more fully
support LDAP directories, some of which are in Tickets already:address completion should incorporate results from an LDAP query
(Ticket #1483899) authenticated bind to an LDAP server (there's a patch floating
around somewhere to hard-code this) expanded query capability (useful for large directories). This
should be kept in mind when adding fields to the local address book.
On an aside, why do all these clients only support read-access to
LDAP? Seems like it would really great to be able to use LDAP in
place of a local address book in all of your clients, but that's not
a possibility if you can't write to it.
I don't get why it is only considered to be useful for reading from.
Something in the design of it?
I wish there was a standard way to replace local address books with a
networked protocol, oh boy do I wish that.
-- Mark Edwards
On Aug 11, 2006, at 12:18 PM, Mark Edwards wrote:
On Aug 11, 2006, at 7:11 AM, Eric Stadtherr wrote:
I agree with not relying solely on LDAP. Requiring LDAP for the
local address book imposes yet another installation/configuration/ maintenance/support requirement on the RoundCube administrator.
Also, for people who are hosting RoundCube on third-part web
servers, LDAP may not even be an option.Having said that, LDAP is a very common directory service provider
for many companies and I think we need to support LDAP seamlessly.
Many e-mail clients (Thunderbird, Apple Mail) support read-only
access to LDAP directories as a supplement to their local address
book. I like this model, which is generally where RoundCube is
headed right now. There are some things we could do to more fully
support LDAP directories, some of which are in Tickets already:address completion should incorporate results from an LDAP query
(Ticket #1483899) authenticated bind to an LDAP server (there's a patch floating
around somewhere to hard-code this) expanded query capability (useful for large directories). This
should be kept in mind when adding fields to the local address book.On an aside, why do all these clients only support read-access to
LDAP? Seems like it would really great to be able to use LDAP in
place of a local address book in all of your clients, but that's
not a possibility if you can't write to it.I don't get why it is only considered to be useful for reading
from. Something in the design of it?
Lightweight Directory Access Protocol was designed to be a
"lightweight directory access protocol". :) That is, it is highly
optimized for many reads, few writes. Contact information should not
change frequently. If you want to do a lot of writes, you use a
database.
-- Jason Dixon DixonGroup Consulting http://www.dixongroup.net
On Aug 11, 2006, at 10:23 AM, Jason Dixon wrote:
On Aug 11, 2006, at 12:18 PM, Mark Edwards wrote:
On an aside, why do all these clients only support read-access to
LDAP? Seems like it would really great to be able to use LDAP in
place of a local address book in all of your clients, but that's
not a possibility if you can't write to it.I don't get why it is only considered to be useful for reading
from. Something in the design of it?Lightweight Directory Access Protocol was designed to be a
"lightweight directory access protocol". :) That is, it is highly
optimized for many reads, few writes. Contact information should
not change frequently. If you want to do a lot of writes, you use
a database.
Right, well it would be great if ANY mail client supported a standard
protocol for networking address books. It just seems absurd that
this hasn't been covered yet.
Anyway, thanks for the answer!
-- Mark Edwards
On Aug 11, 2006, at 1:27 PM, Mark Edwards wrote:
On Aug 11, 2006, at 10:23 AM, Jason Dixon wrote:
On Aug 11, 2006, at 12:18 PM, Mark Edwards wrote:
On an aside, why do all these clients only support read-access to
LDAP? Seems like it would really great to be able to use LDAP in
place of a local address book in all of your clients, but that's
not a possibility if you can't write to it.I don't get why it is only considered to be useful for reading
from. Something in the design of it?Lightweight Directory Access Protocol was designed to be a
"lightweight directory access protocol". :) That is, it is
highly optimized for many reads, few writes. Contact information
should not change frequently. If you want to do a lot of writes,
you use a database.Right, well it would be great if ANY mail client supported a
standard protocol for networking address books. It just seems
absurd that this hasn't been covered yet.
I think that LDAP *is* a standard for "networking address books".
But that doesn't mean that your webmail interface is the right place
to administer it. ;-)
-- Jason Dixon DixonGroup Consulting http://www.dixongroup.net
--See the DB Structure: http://img61.imageshack.us/my.php?image=erdmb5.jpg
Create table contacts ( contact_id Int NOT NULL, changed Datetime, del Tinyint, name Varchar(128), email Varchar(128), firstname Varchar(128), user_id Int, Primary Key (contact_id)) ENGINE = MyISAM;
Create table contact_info_type ( contact_info_type_id Int NOT NULL, display_label Varchar(128), Primary Key (contact_info_type_id)) ENGINE = MyISAM;
Create table contact_info ( contact_id Int NOT NULL, contact_info_type_id Int NOT NULL, value Varchar(128), contact_info_id Int NOT NULL, Primary Key (contact_info_id)) ENGINE = MyISAM;
Alter table contact_info add Foreign Key (contact_id) references contacts (contact_id) on delete restrict on update restrict; Alter table contact_info add Foreign Key (contact_info_type_id) references contact_info_type (contact_info_type_id) on delete restrict on update restrict;
/* I think that the contact_info_type can hold the type of contact info, like organization, telephones, mother name :D and the contact_info has the ones that belongs to the contact. */
2006/8/11, Martin Marques martin@bugs.unl.edu.ar:
On Thu, 10 Aug 2006, Michel Moreira wrote:
I dont think that saving the all the field data in one vcard string is a good idea.
How about searching my contacts that live on some city, some info that is in this vcard string?
It isnt good to add a field to each contact info that is available...
I think that can be created 2 tables, one with the contact info type and one that has an 1-n relationship between the contacts table and tis contact info type table, where u can put the info.
Then u can search freely withouth performance issues and store and extends all the contact info without having too many empty fields.
This is a good idea. can we through some ideas on DB structure?
-- 21:50:04 up 2 days, 9:07, 0 users, load average: 0.92, 0.37, 0.18
Lic. Martín Marqués | SELECT 'mmarques' || Centro de Telemática | '@' || 'unl.edu.ar'; Universidad Nacional | DBA, Programador, del Litoral | Administrador
My idea of the db structure. Sorry about the other message.
2006/8/11, Martin Marques martin@bugs.unl.edu.ar:
On Thu, 10 Aug 2006, Michel Moreira wrote:
I dont think that saving the all the field data in one vcard string is a good idea.
How about searching my contacts that live on some city, some info that is in this vcard string?
It isnt good to add a field to each contact info that is available...
I think that can be created 2 tables, one with the contact info type and one that has an 1-n relationship between the contacts table and tis contact info type table, where u can put the info.
Then u can search freely withouth performance issues and store and extends all the contact info without having too many empty fields.
This is a good idea. can we through some ideas on DB structure?
-- 21:50:04 up 2 days, 9:07, 0 users, load average: 0.92, 0.37, 0.18
Lic. Martín Marqués | SELECT 'mmarques' || Centro de Telemática | '@' || 'unl.edu.ar'; Universidad Nacional | DBA, Programador, del Litoral | Administrador

Michel Moreira wrote:
My idea of the db structure. Sorry about the other message.
I think that can be created 2 tables, one with the contact info type and one that has an 1-n relationship between the contacts table and tis contact info type table, where u can put the info.
Then u can search freely withouth performance issues and store and extends all the contact info without having too many empty fields.
I've gone down that road, and it ain't fun. The problem is that it forces the same display and type on every field, so you can't have a little field for state abbreviation, for instance, and forget about checkboxes (for primary address, eg). Sorting becomes a nightmare, etc. I don't see the huge downside to the big honkin' table of contact information. I really don't see storage size as a big downside, especially compared to cpu cycles. If you really want to get relational you could create sub tables for multiple addresses, phone numbers and e-mail addresses, but that's as far as I would go.
-Charles
How about having an vcard_info table? I really want to go relational :P
2006/8/11, Chuck, Charlie and Charles charles@charlesmcnulty.com:
Michel Moreira wrote:
My idea of the db structure. Sorry about the other message.
I think that can be created 2 tables, one with the contact info type and one that has an 1-n relationship between the contacts table and tis contact info type table, where u can put the info.
Then u can search freely withouth performance issues and store and extends all the contact info without having too many empty fields.
I've gone down that road, and it ain't fun. The problem is that it forces the same display and type on every field, so you can't have a little field for state abbreviation, for instance, and forget about checkboxes (for primary address, eg). Sorting becomes a nightmare, etc. I don't see the huge downside to the big honkin' table of contact information. I really don't see storage size as a big downside, especially compared to cpu cycles. If you really want to get relational you could create sub tables for multiple addresses, phone numbers and e-mail addresses, but that's as far as I would go.
-Charles
On Aug 11, 2006, at 2:08 PM, Michel Moreira wrote:
--See the DB Structure: http://img61.imageshack.us/my.php? image=erdmb5.jpg
No offense, but given the design criteria Thomas mentioned earlier
(iCal-like), doesn't it make more sense to use a "free field"
method? That is, to create a single table of "contact" key/value
pairs associated with the user id? Then you can easily pull all
pairs associated with the user and arrange them according to a known
set of keys (first_name, last_name, email, phone, im_contact, etc).
This approach has worked well in the past for systems like OTRS.
Just my $0.02.
-- Jason Dixon DixonGroup Consulting http://www.dixongroup.net
Jason Dixon wrote:
No offense, but given the design criteria Thomas mentioned earlier (iCal-like), doesn't it make more sense to use a "free field" method? That is, to create a single table of "contact" key/value pairs associated with the user id? Then you can easily pull all pairs associated with the user and arrange them according to a known set of keys (first_name, last_name, email, phone, im_contact, etc).
This approach has worked well in the past for systems like OTRS. Just my $0.02.
I don't like it because it makes things like sorting multiple contacts, sorting by numeric/non-numeric fields, and having fields like check boxes, drop-down lists, etc. needlessly complicated. In essence I don't like it because the more features you want to implement, the more you've moved towards creating a database engine on top of a database engine. In other words there's already a system for creating paired fields and values, and it's called a table.
With the system you propose you gain:
- some flexibility in creating and removing fields
- some storage space
but you lose all of the built in functions of a database engine, such as default data, data types (including date manipulation), etc. What about grouping bits of that data together? Let's say you want a list of all phone numbers for a contact. In a normal contact table you just hang a table off of it called phone_numbers {phone_id; contact_id; description; phone_number} and voila, you have lists of phone numbers. Now imagine trying to do that in the systems being proposed. Sure you can create a single phone number label, but what if you want to allow them to label the phone numbers with "home" "work" "cell" etc. You either have to put that data in the "data" portion, mixing it with the phone numbers (forget about ever sorting by area code), or you have to create unique labels for each type, but then they can't be grouped without having another table grouping all of them by their label.
And this is just one example off of the top of my head. Another one: How do you handle multi-lingual labels? I'm not saying that each of these challenges couldn't be solved, I'm saying that it's a crap load of work and not worth it for the benefit's described so far.
I'm saying this from experience implementing exactly what you're describing for a registration database. At first it seemed totally reasonable to allow the conference department to create their own fields for each event, but in practice it just flat out didn't work. When we finally had to scrap the system and purchase an enterprise system, it was, in essence, a big honkin' table with everything you could possibly want about an event, with the ability to select which database columns you need for any specific form or worksheet. Does it need to be updated occasionally? Yes (for the new credit card verification number, for instance), but very rarely, and the updates are not that painful.
For your own sanity, let the database engine be the database engine, don't try to build a new layer of fields and data on top of a system designed for exactly that.
-Charles
On Aug 11, 2006, at 4:08 PM, Chuck, Charlie and Charles wrote:
Jason Dixon wrote:
No offense, but given the design criteria Thomas mentioned earlier (iCal-like), doesn't it make more sense to use a "free field" method? That is, to create a single table of "contact" key/value pairs associated with the user id? Then you can easily pull all pairs associated with the user and arrange them according to a known set of keys (first_name, last_name, email, phone, im_contact, etc).
This approach has worked well in the past for systems like OTRS.
Just my $0.02.I don't like it because it makes things like sorting multiple
contacts, sorting by numeric/non-numeric fields, and having fields like check boxes, drop-down lists, etc. needlessly complicated. In essence I
don't like it because the more features you want to implement, the more
you've moved towards creating a database engine on top of a database engine. In other words there's already a system for creating paired fields and values, and it's called a table.With the system you propose you gain:
- some flexibility in creating and removing fields
- some storage space
but you lose all of the built in functions of a database engine,
such as default data, data types (including date manipulation), etc. What about grouping bits of that data together? Let's say you want a
list of all phone numbers for a contact. In a normal contact table you just hang a table off of it called phone_numbers {phone_id; contact_id; description; phone_number} and voila, you have lists of phone numbers. Now imagine trying to do that in the systems being proposed. Sure you can create a single phone number label, but what if you want to allow them to label the phone numbers with "home" "work" "cell" etc. You either have to put that data in the "data" portion, mixing it with the phone numbers (forget about ever sorting by area code), or you have to create unique labels for each type, but then they can't be grouped without having another table grouping all of them by their label.
You're absolutely right. Allow me to share with you a puff of
whatever I must have been smoking. ;-)
-- Jason Dixon DixonGroup Consulting http://www.dixongroup.net
You're structure has redundant info in it. When I say redundancy, I saying contacts.contacts_id should just be contacts.id (in table-column writing).
Also, you should use standard data types, not like using tinyint. Boolean should be used there. OK, just checked that MySQL STILL doesn't have a boolean data type. Is a 8bit data type the best way to deal with this?
Let's also add the INSERTs to the contact_info_type table (those are application specific data).
On Fri, 11 Aug 2006, Michel Moreira wrote:
Create table contacts ( contact_id Int NOT NULL, changed Datetime, del Tinyint, name Varchar(128), email Varchar(128), firstname Varchar(128), user_id Int, Primary Key (contact_id)) ENGINE = MyISAM;
Create table contact_info_type ( contact_info_type_id Int NOT NULL, display_label Varchar(128), Primary Key (contact_info_type_id)) ENGINE = MyISAM;
Create table contact_info ( contact_id Int NOT NULL, contact_info_type_id Int NOT NULL, value Varchar(128), contact_info_id Int NOT NULL, Primary Key (contact_info_id)) ENGINE = MyISAM;
Alter table contact_info add Foreign Key (contact_id) references contacts (contact_id) on delete restrict on update restrict; Alter table contact_info add Foreign Key (contact_info_type_id) references contact_info_type (contact_info_type_id) on delete restrict on update restrict;
/* I think that the contact_info_type can hold the type of contact info, like organization, telephones, mother name :D and the contact_info has the ones that belongs to the contact. */
You mean, contact_info has the contact information. That looks good.
-- 21:50:04 up 2 days, 9:07, 0 users, load average: 0.92, 0.37, 0.18
Lic. Martín Marqués | SELECT 'mmarques' || Centro de Telemática | '@' || 'unl.edu.ar'; Universidad Nacional | DBA, Programador, del Litoral | Administrador
On Fri, 11 Aug 2006, Chuck, Charlie and Charles wrote:
I've gone down that road, and it ain't fun. The problem is that it forces the same display and type on every field, so you can't have a little field for state abbreviation, for instance, and forget about checkboxes (for primary address, eg). Sorting becomes a nightmare, etc. I don't see the huge downside to the big honkin' table of contact information. I really don't see storage size as a big downside, especially compared to cpu cycles. If you really want to get relational you could create sub tables for multiple addresses, phone numbers and e-mail addresses, but that's as far as I would go.
I don't share the same thoughts. When is comes to normalizing, and making searches on a huge table, performace will be MAYOR factor if you don't use a normalize relational structure.
Any way, the 2 mayor DB that RC uses (I'm not counting SQLite) are relational, so why not use these feature, which is great.
-- 21:50:04 up 2 days, 9:07, 0 users, load average: 0.92, 0.37, 0.18
Lic. Martín Marqués | SELECT 'mmarques' || Centro de Telemática | '@' || 'unl.edu.ar'; Universidad Nacional | DBA, Programador, del Litoral | Administrador

Martin Marques wrote:
On Fri, 11 Aug 2006, Chuck, Charlie and Charles wrote:
I've gone down that road, and it ain't fun. The problem is that it forces the same display and type on every field, so you can't have a little field for state abbreviation, for instance, and forget about checkboxes (for primary address, eg). Sorting becomes a nightmare, etc. I don't see the huge downside to the big honkin' table of contact information. I really don't see storage size as a big downside, especially compared to cpu cycles. If you really want to get relational you could create sub tables for multiple addresses, phone numbers and e-mail addresses, but that's as far as I would go.
I don't share the same thoughts. When is comes to normalizing, and making searches on a huge table, performace will be MAYOR factor if you don't use a normalize relational structure.
Any way, the 2 mayor DB that RC uses (I'm not counting SQLite) are relational, so why not use these feature, which is great.
-- 21:50:04 up 2 days, 9:07, 0 users, load average: 0.92, 0.37, 0.18
Lic. Martín Marqués | SELECT 'mmarques' || Centro de Telemática | '@' || 'unl.edu.ar'; Universidad Nacional | DBA, Programador, del Litoral | Administrador
Let's also not forget that when searches occur, or any lookup for that
matter, temporary tables are created. So if you have one central table
that links 18 tables of information together, if you query properly and
create a temp table before querying, and SELECT INTO temp_table you
can then run a secondary select on the temp table and order it as you
please.
~Brett
On Fri, 11 Aug 2006 15:31:33 -0400, Jason Dixon jason@dixongroup.net wrote:
On Aug 11, 2006, at 2:08 PM, Michel Moreira wrote:
--See the DB Structure: http://img61.imageshack.us/my.php? image=erdmb5.jpg
No offense, but given the design criteria Thomas mentioned earlier (iCal-like), doesn't it make more sense to use a "free field" method? That is, to create a single table of "contact" key/value pairs associated with the user id? Then you can easily pull all pairs associated with the user and arrange them according to a known set of keys (first_name, last_name, email, phone, im_contact, etc).
I'm lost. Wasn't that what he showed? Or am I not understanding your point?
What we need is this:
- Table with all the posible options for one contact (names, email, phone number, address, web page, etc.). Each of these options would be a registered row of this table.
- Table with the contacts of a RC user. Very simple table that identifies a conetact. All the data for this user would go in the table explained in (3) with a reference to the PK of this table.
- Table with the actual information. For each piece of info of the contaact, there would be a row, with a field referencing to the contract mentioned in (2), the type of option as mentioned in (1) and the value.
That's how I see it. Coments about it?
--
Lic. Martín Marqués | SELECT 'mmarques' || Centro de Telemática | '@' || 'unl.edu.ar'; Universidad Nacional | DBA, Programador, del Litoral | Administrador
On Fri, 11 Aug 2006 15:08:33 -0500, "Chuck, Charlie and Charles" charles@charlesmcnulty.com wrote:
And this is just one example off of the top of my head. Another one: How do you handle multi-lingual labels? I'm not saying that each of these challenges couldn't be solved, I'm saying that it's a crap load of work and not worth it for the benefit's described so far.
You are right Charles.
Do you propose a single big table (lots of columns), or multiple tables for different contact options?
I don't see the first option as resonable.
--
Lic. Martín Marqués | SELECT 'mmarques' || Centro de Telemática | '@' || 'unl.edu.ar'; Universidad Nacional | DBA, Programador, del Litoral | Administrador
On Sat, 12 Aug 2006 09:47:03 -0400, Brett Patterson brett@bpatterson.net wrote:
Martin Marques wrote:
I don't share the same thoughts. When is comes to normalizing, and making searches on a huge table, performace will be MAYOR factor if you don't use a normalize relational structure.
Any way, the 2 mayor DB that RC uses (I'm not counting SQLite) are relational, so why not use these feature, which is great.
Let's also not forget that when searches occur, or any lookup for that matter, temporary tables are created. So if you have one central table that links 18 tables of information together, if you query properly and create a temp table before querying, and SELECT INTO
temp_tableyou can then run a secondary select on the temp table and order it as you please.
I would have to look at RC code closely, but I havn't seen it create temp tables to make searches. Or are you just saying it can be done?
Any way, doing it that way you have a great lose of performace, and should only be done when no query can be written to performe at a resonable rate.
Normally DB structure should never be designed thinking that you have temp tables to use in case of disfavourable search scenario. If there's no other way around it, then it's what has to be done. But else, direct searches are the best bet.
--
Lic. Martín Marqués | SELECT 'mmarques' || Centro de Telemática | '@' || 'unl.edu.ar'; Universidad Nacional | DBA, Programador, del Litoral | Administrador
The db structure of the Initial Database names the primarykeys as <tablename>_id. I thing that should exist an paper with the db design guidelines.
2006/8/12, Martin Marques martin@bugs.unl.edu.ar:
You're structure has redundant info in it. When I say redundancy, I saying contacts.contacts_id should just be contacts.id (in table-column writing).
Also, you should use standard data types, not like using tinyint. Boolean should be used there. OK, just checked that MySQL STILL doesn't have a boolean data type. Is a 8bit data type the best way to deal with this?
Let's also add the INSERTs to the contact_info_type table (those are application specific data).
On Fri, 11 Aug 2006, Michel Moreira wrote:
Create table contacts ( contact_id Int NOT NULL, changed Datetime, del Tinyint, name Varchar(128), email Varchar(128), firstname Varchar(128), user_id Int, Primary Key (contact_id)) ENGINE = MyISAM;
Create table contact_info_type ( contact_info_type_id Int NOT NULL, display_label Varchar(128), Primary Key (contact_info_type_id)) ENGINE = MyISAM;
Create table contact_info ( contact_id Int NOT NULL, contact_info_type_id Int NOT NULL, value Varchar(128), contact_info_id Int NOT NULL, Primary Key (contact_info_id)) ENGINE = MyISAM;
Alter table contact_info add Foreign Key (contact_id) references contacts (contact_id) on delete restrict on update restrict; Alter table contact_info add Foreign Key (contact_info_type_id) references contact_info_type (contact_info_type_id) on delete restrict on update restrict;
/* I think that the contact_info_type can hold the type of contact info, like organization, telephones, mother name :D and the contact_info has the ones that belongs to the contact. */
You mean, contact_info has the contact information. That looks good.
-- 21:50:04 up 2 days, 9:07, 0 users, load average: 0.92, 0.37, 0.18
Lic. Martín Marqués | SELECT 'mmarques' || Centro de Telemática | '@' || 'unl.edu.ar'; Universidad Nacional | DBA, Programador, del Litoral | Administrador

I like it and I do not know why everyone else ignored it neither,
Thomas
Hello,
To make sure that everyone gets what Eric propose I put in in SQL (and added a variation as it could be improved.
[ ALL SQL is just for demontration and may simply not work ]
create table contact ( ownwer_id int not null, contact_id int not null, type_id int not null, key varchar(20) default null, value varchar(20) default null, primary key (owner_id,contact_id,type_id) );
create table contact_type ( type_id int not null, name varchar(20), primary key (type_id) );
alter table contact add foreign key (type_id) references contact_type (type_id) on update cascade on delete cascade;
insert into contact_type values (1,'email'); insert into contact_type values (1,'phone');
insert into contact (1,1,1,'home','him@home'); insert into contact (1,1,1,'work','him@work'); insert into contact (1,2,1,'home','her@home'); insert into contact (1,2,1,'work','her@work');
insert into contact (1,1,2,'home','+44 12744 000000') insert into contact (1,1,2,'work','+44 12744 111111') insert into contact (1,1,2,'fax' ,'+44 12744 222222')
you could as well do something like :
# information stored about a person
create table contact_info ( contact_id int not null, contact_type int not null, /* more contact fields like before ??? */ value text(255), primary key (contact_id,contact_type) )
# Associate a the information with a roundcube user.
create table contact ( contact_id serial not null, owner_id int not null, contact_name text not null, primary_key (contact_id) )
# Type of information stored
create table types ( type_id int not null, type_name text not null, primary key (type_id) )
alter table contact_info add foreign key (contact_id) references contact (contact_id) on delete cascade on update cascade alter table contact_info add foreign key (contact_type) references types (type_id) on update cascade on delete cascade
# Pseudo inserts to make sense of the tables.
insert into contact (owner_id, contact_name) values (CONTACT_DAVID, 'Thomas Mangin'); # creates contact_id CONTACT_THOMAS insert into contact_info (contact_id, contact_type, value) values (CONTACT_THOMAS, TYPE_TELNO, '+44 1274 000000');
On Mon, 14 Aug 2006 18:19:55 +0100, Thomas Mangin thomas.mangin@exa-networks.co.uk wrote:
you could as well do something like :
# information stored about a person
create table contact_info ( contact_id int not null, contact_type int not null, /* more contact fields like before ??? */ value text(255), primary key (contact_id,contact_type) )
# Associate a the information with a roundcube user.
create table contact ( contact_id serial not null, owner_id int not null, contact_name text not null, primary_key (contact_id) )
# Type of information stored
create table types ( type_id int not null, type_name text not null, primary key (type_id) )
alter table contact_info add foreign key (contact_id) references contact (contact_id) on delete cascade on update cascade alter table contact_info add foreign key (contact_type) references types (type_id) on update cascade on delete cascade
# Pseudo inserts to make sense of the tables.
insert into contact (owner_id, contact_name) values (CONTACT_DAVID, 'Thomas Mangin'); # creates contact_id CONTACT_THOMAS insert into contact_info (contact_id, contact_type, value) values (CONTACT_THOMAS, TYPE_TELNO, '+44 1274 000000');
IMHO this is a better approch. The problem is, as Charles mentioned, any kind of data would go in a VARCHAR(255) field, making it dificult to sort by dates or so. I think that if a data type is a date, it should go in a date field, and the same for integer, string, etc.
--
Lic. Martín Marqués | SELECT 'mmarques' || Centro de Telemática | '@' || 'unl.edu.ar'; Universidad Nacional | DBA, Programador, del Litoral | Administrador
IMHO this is a better approch. The problem is, as Charles mentioned, any kind of data would go in a VARCHAR(255) field, making it dificult to sort by dates or so. I think that if a data type is a date, it should go in a date field, and the same for integer, string, etc.
It is a compromise, you can not have a flexible scheme and have precise field type. Otherwise a more classic DB format would do better.
I agree that it is not ideal for sorting but what are we going to sort on ? Contact Name (we can split the Name and Surname in that case - see second BD format).
The phone numbers are string, email are strings, date entered as YYYY/MM/DD can be sorted with strings. it is not most efficient for the SQL DB but it can work.
For the other field, I can not comment as I have no idea what a VCARD contains, and what the devlelopers are planning to achieve.
Thomas

I agree with Thomas - easy sorting isn't the primary objective. We're
mostly trying to simplify storage for a large number of different
fields, many of which may not be provided for any given contact.
Searching would be the next most important consideration. That will
most often be a substring query against a user-provided string, which
this schema supports well.
SELECT contact_id FROM contacts WHERE field_value LIKE '%<string>%'
AND field_type_id IN (<name field type id's>);
If we want to do vCard import/export, we'll need an adapter/ translator of some type regardless of the design of the database schema.
-Eric
On Aug 14, 2006, at 5:56 PM, Thomas Mangin wrote:
IMHO this is a better approch. The problem is, as Charles
mentioned, any kind of data would go in a VARCHAR(255) field,
making it dificult to sort by dates or so. I think that if a data
type is a date, it should go in a date field, and the same for
integer, string, etc.It is a compromise, you can not have a flexible scheme and have
precise field type. Otherwise a more classic DB format would do
better.I agree that it is not ideal for sorting but what are we going to
sort on ? Contact Name (we can split the Name and Surname in that
case - see second BD format).The phone numbers are string, email are strings, date entered as
YYYY/MM/DD can be sorted with strings. it is not most efficient for
the SQL DB but it can work.For the other field, I can not comment as I have no idea what a
VCARD contains, and what the devlelopers are planning to achieve.Thomas
On Mon, 14 Aug 2006, Eric Stadtherr wrote:
Thomas,
I wouldn't put the cascade delete on the type constraint, though (you don't want to lose the ability to enter phone numbers just because you deleted your last phone number... Wink ).
On CASCADE means that if you eliminate or update a PK, it will cascade to the refereced keys. If you eliminate the last phone number, you're just eliminating rows that reference th PK, so no CASCADE is done.
Those CASCADE are more like, if you eliminate the contact, all the info of that contact will be eliminated.
-- 21:50:04 up 2 days, 9:07, 0 users, load average: 0.92, 0.37, 0.18
Lic. Martín Marqués | SELECT 'mmarques' || Centro de Telemática | '@' || 'unl.edu.ar'; Universidad Nacional | DBA, Programador, del Litoral | Administrador
Martin,
I understand the intent of the CASCADE, I was just under the impression that the "contact_type" table in your first example (or the contact_field_type table in my version) were "static" tables that defined the existence of certain field types (phone number, email, birthday, first name, last name, etc.). The type column in the contact table would then reference the PK of the "type" table (through the FK constraint) to describe which type of field was contained in that row. You then wouldn't want to delete your type entry if there were no referencing contact entries. Does this make sense? -Eric
Martin Marques wrote:
On Mon, 14 Aug 2006, Eric Stadtherr wrote:
Thomas,
I wouldn't put the cascade delete on the type constraint, though (you don't want to lose the ability to enter phone numbers just because you deleted your last phone number... Wink ).
On CASCADE means that if you eliminate or update a PK, it will cascade to the refereced keys. If you eliminate the last phone number, you're just eliminating rows that reference th PK, so no CASCADE is done.
Those CASCADE are more like, if you eliminate the contact, all the info of that contact will be eliminated.
-- 21:50:04 up 2 days, 9:07, 0 users, load average: 0.92, 0.37, 0.18
Lic. Martín Marqués | SELECT 'mmarques' || Centro de Telemática | '@' || 'unl.edu.ar'; Universidad Nacional | DBA, Programador, del Litoral | Administrador
On Tue, 15 Aug 2006, Eric Stadtherr wrote:
Martin,
I understand the intent of the CASCADE, I was just under the impression that the "contact_type" table in your first example (or the contact_field_type table in my version) were "static" tables that defined the existence of certain field types (phone number, email, birthday, first name, last name, etc.). The type column in the contact table would then reference the PK of the "type" table (through the FK constraint) to describe which type of field was contained in that row. You then wouldn't want to delete your type entry if there were no referencing contact entries. Does this make sense?
Are we talking about the same structure?
<sql code> alter table contact_info add foreign key (contact_id) references contact (contact_id) on delete cascade on update cascade alter table contact_info add foreign key (contact_type) references types (type_id) on update cascade on delete cascade </sql code>
In this case, the contact info (your phone numbers, email addresses, etc.) will get deleted, IF the contact is deleted. That's a good policy, else you'll have garbage in the DB.
-- 21:50:04 up 2 days, 9:07, 0 users, load average: 0.92, 0.37, 0.18
Lic. Martín Marqués | SELECT 'mmarques' || Centro de Telemática | '@' || 'unl.edu.ar'; Universidad Nacional | DBA, Programador, del Litoral | Administrador
Martin,
We're talking about the same structure, and I completely agree with you about the contact_info->contact foreign key. I wouldn't include the cascading delete on the second FK, though (the contact_info->types reference), since the types contents should be relatively static and you want the database to prevent you from deleting types if there are referring contact_info rows.
Thoughts?
-Eric
On Tue, 15 Aug 2006, Eric Stadtherr wrote:
Martin,
I understand the intent of the CASCADE, I was just under the impression
that
the "contact_type" table in your first example (or the
contact_field_type
table in my version) were "static" tables that defined the existence of certain field types (phone number, email, birthday, first name, last
name,
etc.). The type column in the contact table would then reference the PK
of
the "type" table (through the FK constraint) to describe which type of
field
was contained in that row. You then wouldn't want to delete your type
entry
if there were no referencing contact entries. Does this make sense?
Are we talking about the same structure?
<sql code> alter table contact_info add foreign key (contact_id) references contact (contact_id) on delete cascade on update cascade alter table contact_info add foreign key (contact_type) references types (type_id) on update cascade on delete cascade </sql code>
In this case, the contact info (your phone numbers, email addresses, etc.)
will get deleted, IF the contact is deleted. That's a good policy, else you'll have garbage in the DB.
-- 21:50:04 up 2 days, 9:07, 0 users, load average: 0.92, 0.37, 0.18
Lic. Martín Marqués | SELECT 'mmarques' || Centro de Telemática | '@' || 'unl.edu.ar'; Universidad Nacional | DBA, Programador, del Litoral | Administrador
On Thu, 17 Aug 2006, Eric Stadtherr wrote:
Martin,
We're talking about the same structure, and I completely agree with you about the contact_info->contact foreign key. I wouldn't include the cascading delete on the second FK, though (the contact_info->types reference), since the types contents should be relatively static and you want the database to prevent you from deleting types if there are referring contact_info rows.
Thoughts?
I agree with the fact that types should be a INSERT only table, but it a type is deleted, what do you do with the contact_info? If you are saying that if a type has been used in the contact_info table, you can't delete it, then you are right: there shouldn't be a cascade.
-- 21:50:04 up 2 days, 9:07, 0 users, load average: 0.92, 0.37, 0.18
Lic. Martín Marqués | SELECT 'mmarques' || Centro de Telemática | '@' || 'unl.edu.ar'; Universidad Nacional | DBA, Programador, del Litoral | Administrador
Hopefully I said the SQL was there for demo purpose and may not be right :)
Thomas

Is anyone else experiencing this? While a message is open, the
delete button does nothing. They can only be deleted by returning to
the main list.
Ken

{kind=link}
{kind=link}
{kind=link}

Works just fine for me...
On Tue, 03 Oct 2006 22:36:55 -0500, Matt Kaatman roundcube-dev@matt.kaatman.com wrote:
Yes. I too have that issue.
Ken Samland wrote:
Is anyone else experiencing this? While a message is open, the delete button does nothing. They can only be deleted by returning to the main list.
Ken
On Tue, 3 Oct 2006 22:50:14 -0400, Ken Samland ksamland@wilson.wnyric.org wrote:
Is anyone else experiencing this? While a message is open, the delete button does nothing. They can only be deleted by returning to the main list.
This, as well as some other things, is broken in SVN versions; I think this happened sometime last week. I have a script to update each night, so SVN has been pretty much unusable for me for a week (now when I click on a message to read it won't open the message, so I have to open up the Beta to check my mail). I haven't had time to enter any bugs, will do a fresh checkout/database update before I write any, but if anyone else is/isn't having these issues, please share.
I suspect we may be somewhat dead in the water until Thomas comes back, unless some recent commiters have fixes in mind.
P
Ken
-- This message has been scanned for viruses and dangerous content by MailScanner, and is believed to be clean.
-- http://fak3r.com - you don't have to kick it
On Wed, 4 Oct 2006 10:39:26 +0100, Keith Douglas kdouglas@netsoc.dit.ie wrote:
Works just fine for me...
Really? Running SVN? I'm going to pull down fresh SVN, redo my config by hand and create a new DB to test it; really like how SVN 'breaks up' the conversation when replying. I'll give it a go and post results here later, thanks.
P
On Tue, 03 Oct 2006 22:36:55 -0500, Matt Kaatman roundcube-dev@matt.kaatman.com wrote:
Yes. I too have that issue.
Ken Samland wrote:
Is anyone else experiencing this? While a message is open, the delete button does nothing. They can only be deleted by returning to the main list.
Ken
-- http://fak3r.com - you don't have to kick it

On Wed, 4 Oct 2006 9:04:42 -0500, phil phil@cryer.us wrote:
On Tue, 3 Oct 2006 22:50:14 -0400, Ken Samland ksamland@wilson.wnyric.org wrote:
Is anyone else experiencing this? While a message is open, the delete button does nothing. They can only be deleted by returning to the main list.
This, as well as some other things, is broken in SVN versions; I think this happened sometime last week. I have a script to update each night, so SVN has been pretty much unusable for me for a week (now when I click on a message to read it won't open the message, so I have to open up the Beta to check my mail). I haven't had time to enter any bugs, will do a fresh checkout/database update before I write any, but if anyone else is/isn't having these issues, please share.
I have certainly noticed the same thing on my system. I also have a script I use to get the latest SVN rev.
I reverted back to rev. 353 and it is fine. Thomas "broke" this when he did his big change before going on holidays (rev.354).
Others (and me) have reported this in trac (#1484054 and #1484044).
I have not noticed any other (big) bugs with the latest revs. But I don't use the HTML editor at all.
I suspect we may be somewhat dead in the water until Thomas comes back, unless some recent commiters have fixes in mind.
Quite possible, but hopefully not. This is a rather annoying bug that seems to affect many/most/all users(?). Usability is near nill with current trunk. But we can always revert back to rev 353 or earlier, so not that big of a deal.
Unfortunately my JS skills are near non-existent, so I can't offer much help here. Perhaps this weekend if no one else has fixed it by then.
P
Ken
On Wed, 4 Oct 2006 9:19:08 -0500, phil phil@cryer.us wrote:
On Wed, 4 Oct 2006 10:39:26 +0100, Keith Douglas kdouglas@netsoc.dit.ie wrote:
Works just fine for me...
Really? Running SVN? I'm going to pull down fresh SVN, redo my config by hand and create a new DB to test it; really like how SVN 'breaks up' the conversation when replying. I'll give it a go and post results here later, thanks.
Well, after updating fresh from SVN, and using a fresh DB now everything works in SVN again, save for that 'Deleting from within the message'. Cool, glad I didn't write any bugs yet! ;)
P
P
On Tue, 03 Oct 2006 22:36:55 -0500, Matt Kaatman roundcube-dev@matt.kaatman.com wrote:
Yes. I too have that issue.
Ken Samland wrote:
Is anyone else experiencing this? While a message is open, the delete button does nothing. They can only be deleted by returning to the main list.
Ken
-- http://fak3r.com - you don't have to kick it
On Wed, 4 Oct 2006 10:39:26 +0100, Keith Douglas kdouglas@netsoc.dit.ie wrote:
On Tue, 03 Oct 2006 22:36:55 -0500, Matt Kaatman roundcube-dev@matt.kaatman.com wrote:
Yes. I too have that issue.
Ken Samland wrote:
Is anyone else experiencing this? While a message is open, the delete button does nothing. They can only be deleted by returning to the main list.
Ken
Also, when you're on the main list and you delete a message, the highlight disappears; it's supposed to highlight the next available.
P
-- http://fak3r.com - you don't have to kick it
-
 Brett Patterson
Brett Patterson -
 Chuck, Charlie and Charles
Chuck, Charlie and Charles -
 Eric Stadtherr
Eric Stadtherr -
 Jason Dixon
Jason Dixon -
 Keith Douglas
Keith Douglas -
 Ken Samland
Ken Samland -
 Kirktis
Kirktis -
 Mark Edwards
Mark Edwards -
 Martin Marques
Martin Marques -
 Martin Moeller
Martin Moeller -
 Matt Kaatman
Matt Kaatman -
 Michael Bueker
Michael Bueker -
 Michel Moreira
Michel Moreira -
 phil
phil -
 Thomas Bruederli
Thomas Bruederli -
 Thomas Mangin
Thomas Mangin -
 Tobias 'tri' Richter
Tobias 'tri' Richter -
 Tor Bendiksen
Tor Bendiksen